Configuring application-level health monitors for Connect on BIG-IP Local Traffic Manager
Challenge: In order to make sure that the BIG-IP LTM performs failover in case one of the application servers in a cluster/pool should hang, you will want to make certain that the VIP that points to the application server pool is configured with an application-level health monitor. If you simply probe the health of the Connect servers with a default health monitor at the level of the IP stack, then there are potential cases when the BIG-IP LTM might send traffic to a server with a non-responsive application that only seems alive to lower-level probing mechanisms such as the packet Internet groper (PING). Always set the health monitor to probe for an actual string of content on the Connect server; all high-end hardware-based load-balancing devices (HLD) offer application-level health monitoring. The configuration of the monitor may not always be intuitive as each HLD has a different interface and different means of probing an application, but the following guidance will help you get an appropriate monitor in place on BIG-IP LTM as well as demonstrate the concept for implementation with other HLDs.
Example: Consider that you have three server pools and three VIPs. The only VIP and pool combination that needs an application-level health monitor for failover is the Connect application HTTPS server VIP and pool:
HTTPS VIP: connect.adobe.com: 10.10.10.1:443 points to Connect servers: 192.168.0.1: 443 and 192.168.0.2: 443
The probe or health monitor should point to a string on each Connect Enterprise server in its pool to check the health of each server. If one of the servers in the pool becomes non-responsive, the monitor will mark the server down and the HLD will redirect all traffic to the remaining server.
The Connect Meeting server VIP/pool combinations do not need a health monitor because the Connect application server pool handles failover for the Connect meeting rooms:
RTMPS VIP: meeting1.adobe.com: 10.10.10.2:443 points to Connect Meeting server meeting1 192.168.0.1: 1935
RTMPS VIP: meeting2.adobe.com: 10.10.10.3:443 points to Connect Meeting server meeting2 192.168.0.2: 1935
Because there is only one server in each pool, there is no place for the HLD to redirect meeting traffic should one of the Acrobat Connect Professional meeting servers fail to respond. The only reason to probe the Connect Meeting server VIP/pool combinations might be to trigger an email message to an administrator to warn that one of the Connect Meeting servers is problematic and that the application pool has triggered failover.
What to do: The best string on the servers that you may point your application-level health monitor towards is the testbuilder diagnostic page:
Note: In Connect 9.8 and prior, an HTTP 1.0 health-check string would work. With Connect 10 however, due to a Tomcat upgrade, you must use an HTTP 1.1 string as shown below.
/servlet/testbuilder
The testbuilder page will send back the “status-ok” string.
It is best to point the health monitor to the testbuilder page rather than a simple HTML string, because testbuilder is actually probing the Connect Enterprise database to make sure there is a healthy connection. If there is any problem with the Connect server application, then testbuilder will not report the “status-ok” string.
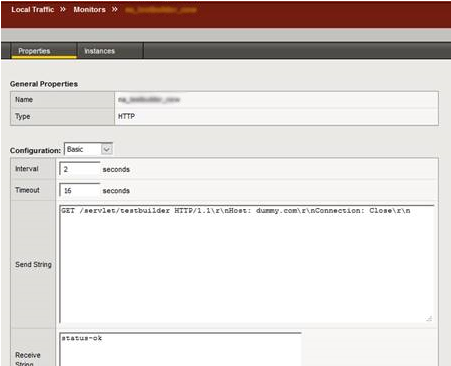
Each HLD has a different interface to configure these monitors and each one does the check differently, the following example works with F5 BIG-IP LTM against testbuilder:
send “GET /servlet/testbuilder HTTP/1.1\nHost: \nConnection: Close \n\r\n”
“status-ok”
For an LTM-based monitor called connect_testbuilder:
monitor connect_testbuilder {
defaults from http
recv “status-ok”
send “GET /servlet/testbuilder HTTP/1.1\nHost: \nConnection: Close \n\r\n”
}
Note: Fror more information on the output from testbuilder see the following tech-note: Testbuilder Status Explained
Consider this: You should also place an HTML file in the Connect /common directory on each Connect Enterprise server and point to that file (test access to the html file via a browser to be sure that it does not require a log-in – the help sub-directory under the common directory is also OK with all prior versions of Connect). This option should be used along with testbuilder as a separate and supporting health check. The following example shows an HTML file called healthmonitortarget.html containing the string You are being served HTML”
send “GET /common/help/healthmonitortarget.html”
“You are being served HTML”
Note: With reference to the testbuilder file output behavior, if, for example, Connect receives a SQL Exception (DB Down, or other SQL anomaly) it does not change the output string of testbuilder, Connect tries to reconnect and only when it cannot reconnect to SQL, then it fails over, and then ultimately restarts Connect. If you have the JDBC restart string in place for SQL robustness (and you should if you do not) in the custom.ini file then, in theory, this is desirable behavior:
DB_URL_CONNECTION_RETRY_COUNT=15
DB_URL_CONNECTION_RETRY_DELAY=30
If Connect was more aggressive in the changing of testbuilder or in other words if testbuilder were more sensitive to every acute interruption in the DB connection or the state of the Connect server, then it could trigger superfluous failover at the application VIP on the HLB by marking down a server that may only have a brief reconnection attempts in process to the Connect DB. If Connect fails and restarts due to a DB connection problem and is still unable to connect to the DB once the server restarts, testbuilder will show the following output and trigger the healthmonitor on the HLB appropriately:
“2
status-critical”
If you set up the healthmonitors as described above, then what testbuilder may miss, the HTML health monitor will pick up and vice versa. The key thing is to test the healthmonitors vigorously and inspect the Connect debug logs for any errors they may generate. Since each HLB acts differently and often SSL profiles and other variables will affect behavior, it is prudent to test the health monitors under all server failover conditions.
Be careful: There are hazards commensurate with health monitors; the first concern is that when they are set up incorrectly, the cluster becomes instantly inaccessible through the VIP because the HLD marks all the servers down. Another hazard is with pointing the health check to a page that generates entries in the Connect database. Examples of the latter include hitting the Connect log-in page with a health monitor every few seconds thereby bloating the database with superfluous logging activity. Don’t be like the Second Lieutenant who runs into battle with the loaded .45 pointed at his foot.
Troubleshooting: When a heath check fails, you may look in the Connect debug log for information about the cause. A health monitor pointing to a Connect server-based resource that requires a log in will fail; the monitor is incapable of parsing a log-in. The testbuilder page does not require a log-in and neither should any HTML-based health target in the common directory.